On September 19th, at the Apsara Conference, Alibaba Cloud released the new generation of open-source large language model, Qwen 2.5. It is surprising to notice that the flagship model Qwen 2.5-72B outperforms Llama 3.1-405B, once again claiming the top of global open-source large language models. Features of Qwen 2.5 are:
- Dense, easy-to-use, decoder-only language models, available in 0.5B, 1.5B, 3B, 7B, 14B, 32B, and 72B sizes, and base and instruct variants.
- Pretrained on our latest large-scale dataset, encompassing up to 18T tokens.
- Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON.
- More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.
- Context length support up to 128K tokens and can generate up to 8K tokens.
- Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
For more details, please refer to the release blog post of Qwen 2.5: https://qwenlm.github.io/blog/qwen2.5/
In this article, we will cover running the entire series of Qwen 2.5 models on GPUStack, including Qwen 2.5, the programming-specific Qwen 2.5-Coder, and the math-focused Qwen 2.5-Math, reviewing their performance and resource consumption.
Running the Full Series of Qwen 2.5
Installing GPUStack
Here we will use a Mac Studio and a Ubuntu PC with dual 4080 GPUs to form a two-node heterogeneous GPU cluster, the Mac Studio runs as both Server and Worker, and the Ubuntu PC runs as a Worker. The Server role provides control plane, and the Worker role provides computational resources to run LLMs.
First, install GPUStack on the Mac Studio. GPUStack provides an installation script that allows GPUStack to run as a launchd service on macOS. For more installation scenarios, check the official GPUStack documentation: https://docs.gpustack.ai/.
Run the following command to install GPUStack on the Mac Studio:
xxxxxxxxxx curl -sfL https://get.gpustack.ai | sh -When you see the following output, it means you have successfully deployed and started GPUStack.
xxxxxxxxxx[INFO] Install complete. Run "gpustack" from the command line.Next, get the initial admin password for logging in to GPUStack by running the following command:
xxxxxxxxxxcat /var/lib/gpustack/initial_admin_passwordGo to the browser and access http://myserver (replace the IP address or domain name with the actual value) with the admin username and the initial password obtained previously to log in to GPUStack.
Now, set a new password and log in to GPUStack.
Next, we will add the Ubuntu PC as a worker node to the GPUStack cluster.
Check GPUStack menu and click Resources, then click Add Worker and follow the instructions to continue:
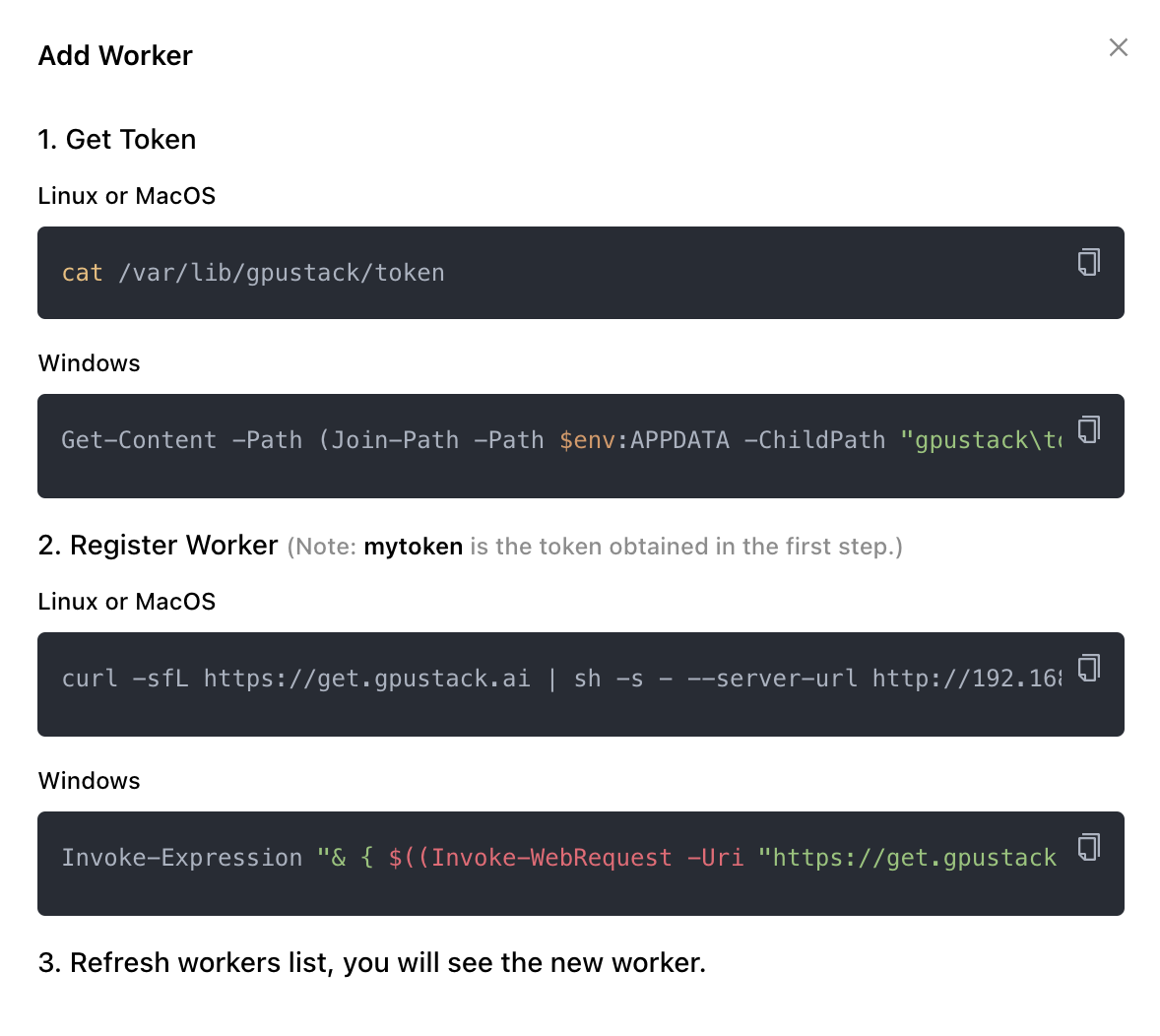
Copy the command to get token and run it on the GPUStack server:
xxxxxxxxxxcat /var/lib/gpustack/tokenNext, run following command to register the worker and run it on the Ubuntu PC, replacing mytoken with the token obtained in the previous step:
xxxxxxxxxxcurl -sfL https://get.gpustack.ai | sh -s - --server-url http://192.168.50.4 --token mytokenThen the worker can be found in the cluster on the GPUStack:

Now switch to GPUs tab, you can see an Apple M2 Ultra GPU and two NVIDIA RTX 4080 GPUs:

For other installation scenarios, refer to the official GPUStack installation documentation: https://docs.gpustack.ai/quickstart/
Running Qwen 2.5
Go to the menu on the left side to navigate to the Models, we will deploy the following models from Hugging Face (all models selected for Qwen 2.5 are quantized using the Q4_K_M method):
- Qwen/Qwen2.5-0.5B-Instruct-GGUF qwen2.5-0.5b-instruct-q4_k_m.gguf
- Qwen/Qwen2.5-1.5B-Instruct-GGUF qwen2.5-1.5b-instruct-q4_k_m.gguf
- Qwen/Qwen2.5-3B-Instruct-GGUF qwen2.5-3b-instruct-q4_k_m.gguf
- Qwen/Qwen2.5-7B-Instruct-GGUF qwen2.5-7b-instruct-q4_k_m*.gguf
- Qwen/Qwen2.5-14B-Instruct-GGUF qwen2.5-14b-instruct-q4_k_m*.gguf
- Qwen/Qwen2.5-32B-Instruct-GGUF qwen2.5-32b-instruct-q4_k_m*.gguf
- Qwen/Qwen2.5-72B-Instruct-GGUF qwen2.5-72b-instruct-q4_k_m*.gguf
- Qwen/Qwen2.5-Coder-1.5B-Instruct-GGUF qwen2.5-coder-1.5b-instruct-q4_k_m.gguf
- Qwen/Qwen2.5-Coder-7B-Instruct-GGUF qwen2.5-coder-7b-instruct-q4_k_m*.gguf

Testing Qwen 2.5 Models
Testing on chat models:

Testing on Coder models:

Testing on Math model:
Checking VRAM and RAM allocation for the models:
- Qwen 2.5 series models
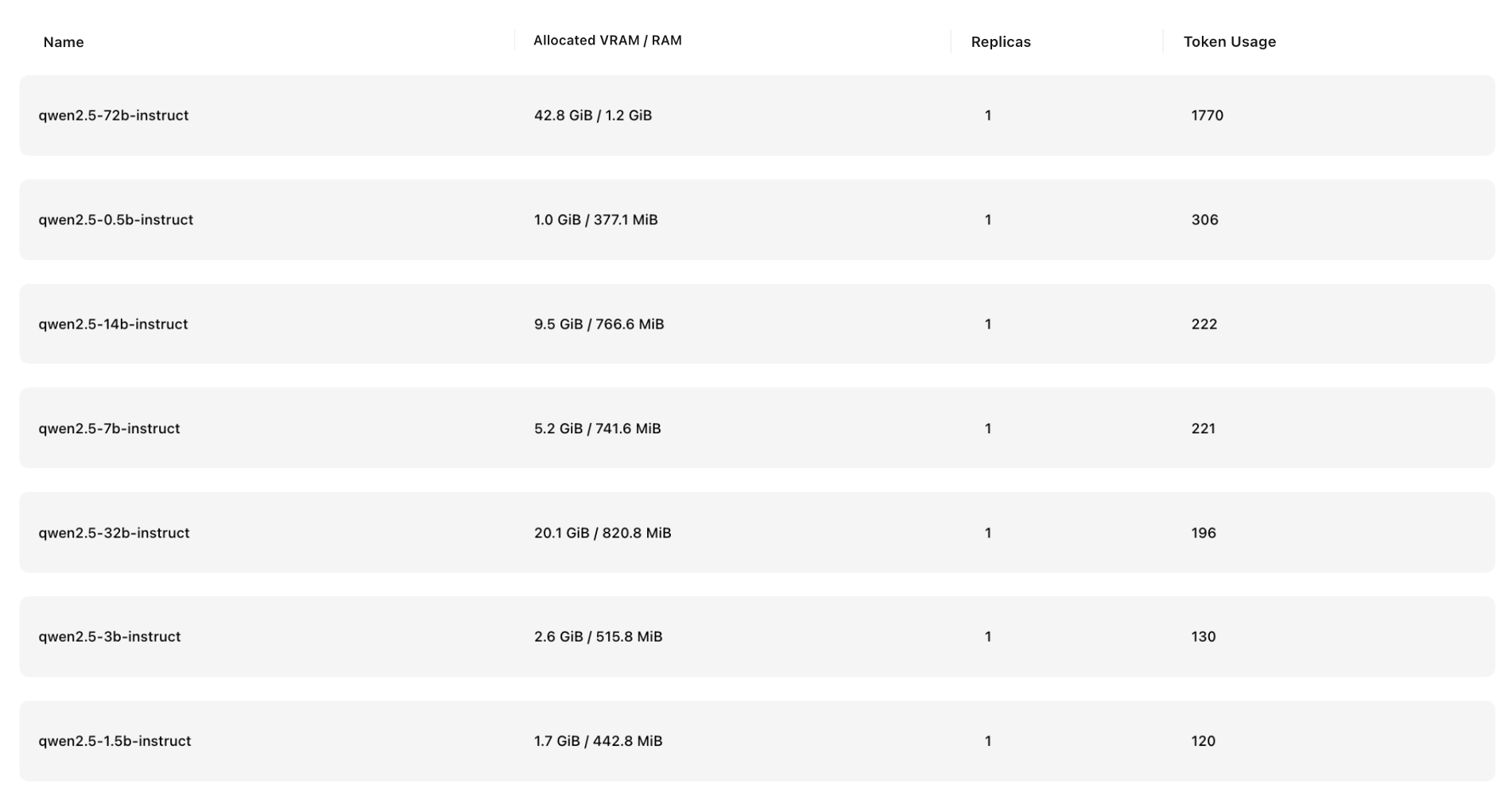
- Qwen2.5-Coder 与 Qwen2.5-Math

Test result is collected as follows:
| Name | Tokens/s | TPOT | TTFT | Allocated VRAM | Allocated RAM | Remarks |
|---|---|---|---|---|---|---|
| qwen2.5-0.5b-instruct | RTX 4080:454.7 M2 Ultra:212.11 | RTX 4080:2.17 ms M2 Ultra:4.71 ms | RTX 4080:16.91 ms M2 Ultra:95.99 ms | 1.0 GiB | 377.1 MiB | |
| qwen2.5-1.5b-instruct | RTX 4080:301.48 M2 Ultra:138.69 | RTX 4080:3.32 ms M2 Ultra:7.21 ms | RTX 4080:17.82 ms M2 Ultra:116.85 ms | 1.7 GiB | 442.8 MiB | |
| qwen2.5-3b-instruct | RTX 4080:201.93 M2 Ultra:106.67 | RTX 4080:4.95 ms M2 Ultra:9.38 ms | RTX 4080:21.2 ms M2 Ultra:168.9 ms | 2.6 GiB | 515.8 MiB | |
| qwen2.5-7b-instruct | RTX 4080:124.42 M2 Ultra:76.69 | RTX 4080:8.04 ms M2 Ultra:13.04 ms | RTX 4080:24.31 ms M2 Ultra:264.97 ms | 5.2 GiB | 741.6 MiB | |
| qwen2.5-14b-instruct | RTX 4080:66.13 M2 Ultra:42.31 | RTX 4080:15.12 ms M2 Ultra:23.64 ms | RTX 4080:47.51 ms M2 Ultra:468.85 ms | 9.5 GiB | 766.6 MiB | |
| qwen2.5-32b-instruct | 22.65 | 44.14 ms | 1436.63 ms | 20.1 GiB | 820.8 MiB | Single RTX 4080 unable to run |
| qwen2.5-72b-instruct | 11.33 | 88.24 ms | 2163.06 ms | 42.8 GiB | 1.2 GiB | Single RTX 4080 unable to run |
| qwen2.5-coder-1.5b-instruct | RTX 4080:297.3 M2 Ultra:138.09 | RTX 4080:3.36 ms M2 Ultra:7.24 ms | RTX 4080:29.34 ms M2 Ultra:130.49 ms | 1.1 GiB | 292.8 MiB | |
| qwen2.5-coder-7b-instruct | RTX 4080:124.42 M2 Ultra:75 | RTX 4080:8.04 ms M2 Ultra:13.33 ms | RTX 4080:39.24 ms M2 Ultra:294.41 ms | 5.2 GiB | 741.6 MiB | |
| qwen2.5-math-1.5b-instruct | 131.36 | 7.61 ms | 119.67 ms | 1.6 GiB | 434.8 MiB | M2 Ultra GPU |
| qwen2.5-math-7b-instruct | 72.02 | 13.89 ms | 1092.11 ms | 4.3 GiB | 583.6 MiB | M2 Ultra GPU |
| qwen2.5-math-72b-instruct | 10.52 | 95.06 ms | 2926.9 ms | 44.8 GiB | 1.2 GiB | M2 Ultra GPU |
Note:
- The performance data is based on tests conducted on the Apple M2 Ultra GPU and the NVIDIA RTX 4080 GPU. Performance on other GPUs may vary due to differences in computational power, VRAM bandwidth, and other factors.
- The maximum context size limit for the models is 8K.
- The Math models were all run on the M2 Ultra GPU. Answer accuracy may be affected by factors such as computational power and quantization. For instance, anomalies in the model may occur due to insufficient computational power or excessively high GPU utilization. The results are for reference only.
Join Our Community
Please find more information about GPUStack at: https://gpustack.ai.
If you encounter any issues or have suggestions for GPUStack, feel free to join our Community for support from the GPUStack team and to connect with fellow users globally.
We are actively enhancing the GPUStack project and plan to introduce new features in the near future, including support for multimodal models, additional accelerators like AMD ROCm or Intel oneAPI, and more inference engines. Before getting started, we encourage you to follow and star our project on GitHub at gpustack/gpustack to receive instant notifications about all future releases. We welcome your contributions to the project.











{kind=link}