
AnythingLLM [https://github.com/Mintplex-Labs/anything-llm] is an all-in-one AI application that runs on Mac, Windows, and Linux. Its goal is to enable the local creation of a personal ChatGPT using either commercial or open-source LLMs along with vector database solutions. AnythingLLM goes beyond being a simple chatbot by including Retrieval-Augmented Generation (RAG) and Agent capabilities. These features allow it to perform a variety of tasks, such as fetching website information, generating charts, summarizing documents, and more.
AnythingLLM can integrate various types of documents into different workspaces, enabling users to reference document content during chats. This provides a easy way to organize workspaces for different tasks and documents.
In this article, we will introduce how to build a personal ChatGPT with knowledge base using AnythingLLM + GPUStack.
Run models with GPUStack
GPUStack is an open-source GPU cluster manager for running large language models (LLMs). It enables you to create a unified cluster from GPUs across various platforms, including Apple MacBooks, Windows PCs, and Linux servers. Administrators can deploy LLMs from popular repositories like Hugging Face, allowing developers to access these models as easily as they would access public LLM services from providers such as OpenAI or Microsoft Azure.
Unlike Ollama, GPUStack is a cluster solution designed to aggregate GPU resources from multiple devices to run models.
To deploy the Chat Model and Embedding Model on GPUStack:
• Chat Model: llama3.1
• Embedding Model: bge-m3
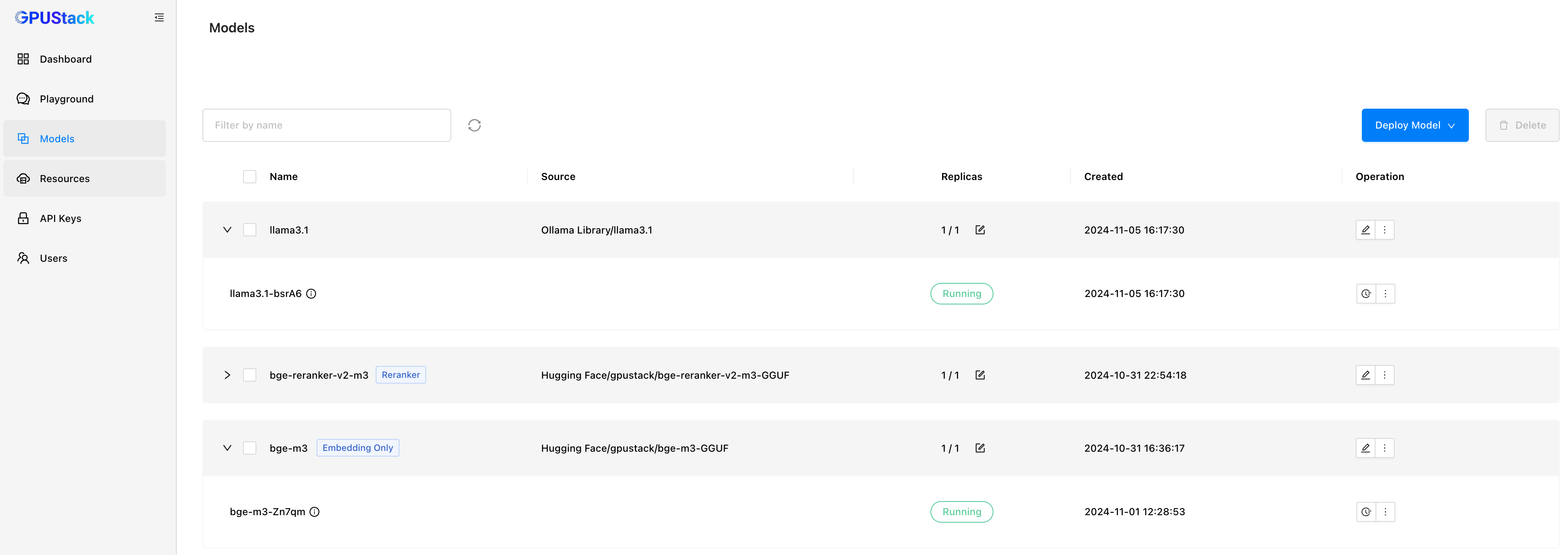
And you need to create an API key. This key will be used by AnythingLLM to authenticate when accessing the models API deployed on GPUStack.
Install and configure AnythingLLM
AnythingLLM offers packages for Mac, Windows, and Linux, you can download from https://anythingllm.com/download. After installation, open AnythingLLM to begin the setup process.
Configure LLM Provider
First, configure the chat model. Search for OpenAI, select Generic OpenAI:

And fill in the details for the model deployed on GPUStack:
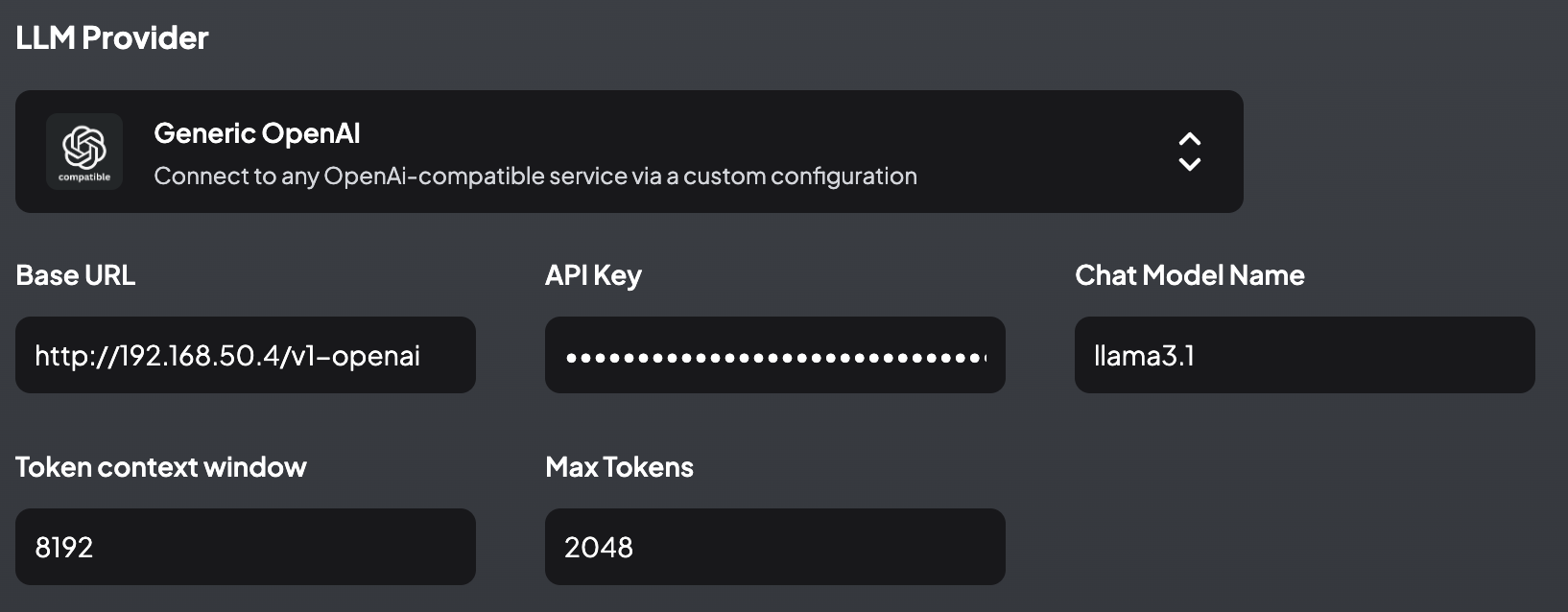
Save and configure embedding model.
Configure Embedding Provider
AnythingLLM includes a lightweight embedding model, all-MiniLM-L6-v2, which offers limited performance and context length. For more powerful embedding capabilities, you can either opt for public embedding services or run open-source embedding models. Here, we’ll configure the embedding model bge-m3, which is running on GPUStack. Set the embedding provider to Generic OpenAI and fill in the relevant configuration.
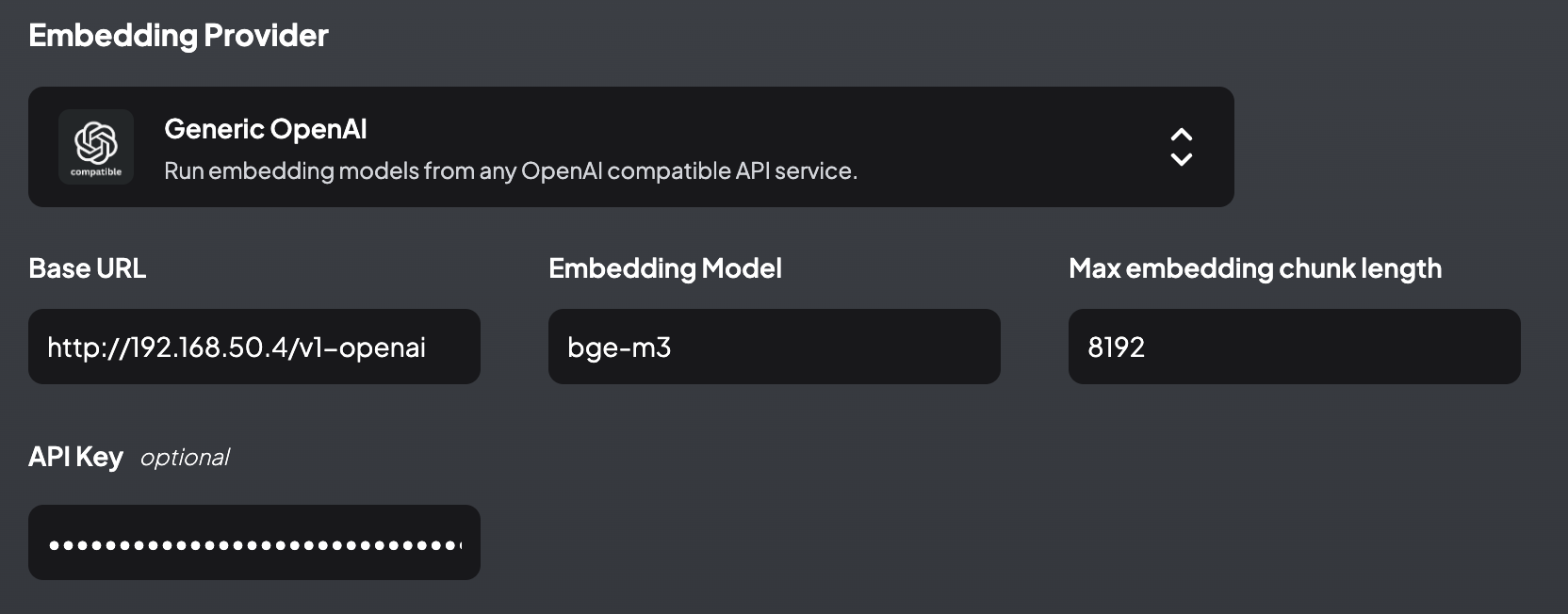
Then create a workspace, and we can use AnythingLLM after it's completed.
Use AnythingLLM
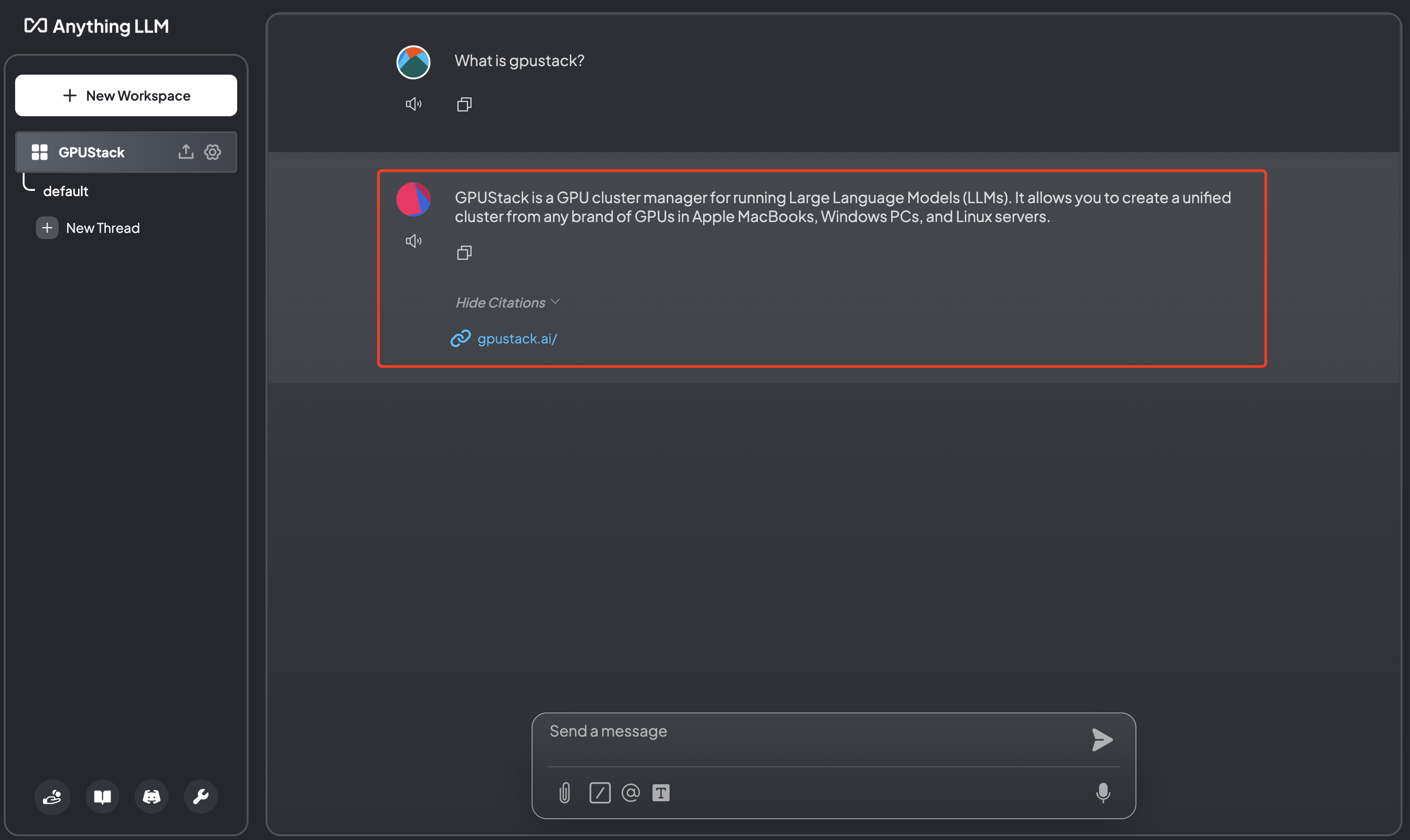
Chat with LLM
Select a workspace, create a new thread, and send your question to the LLM:
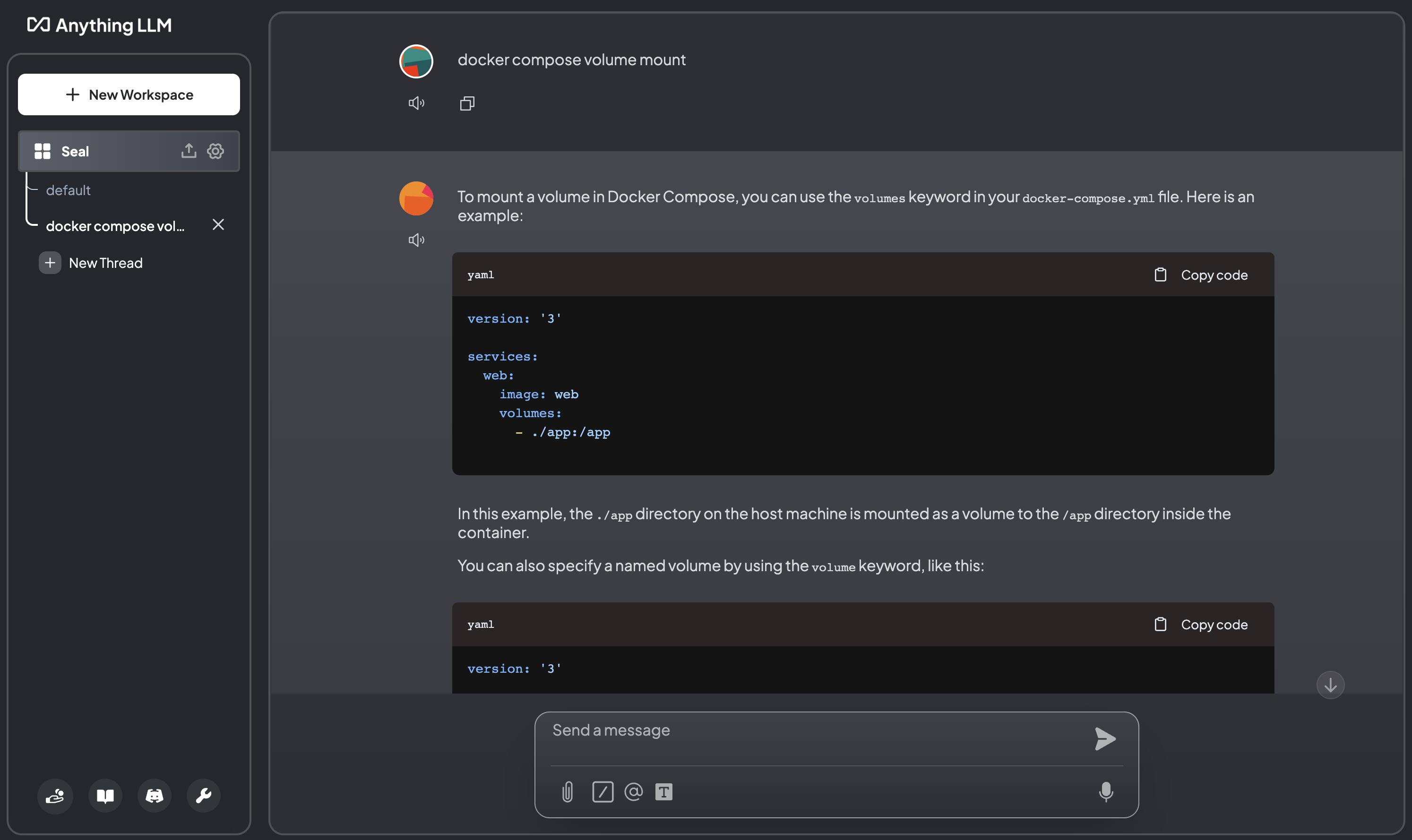
Fetch website content
Click the upload button next to the workspace, enter the website URL in the Fetch website box, and fetch the website content.
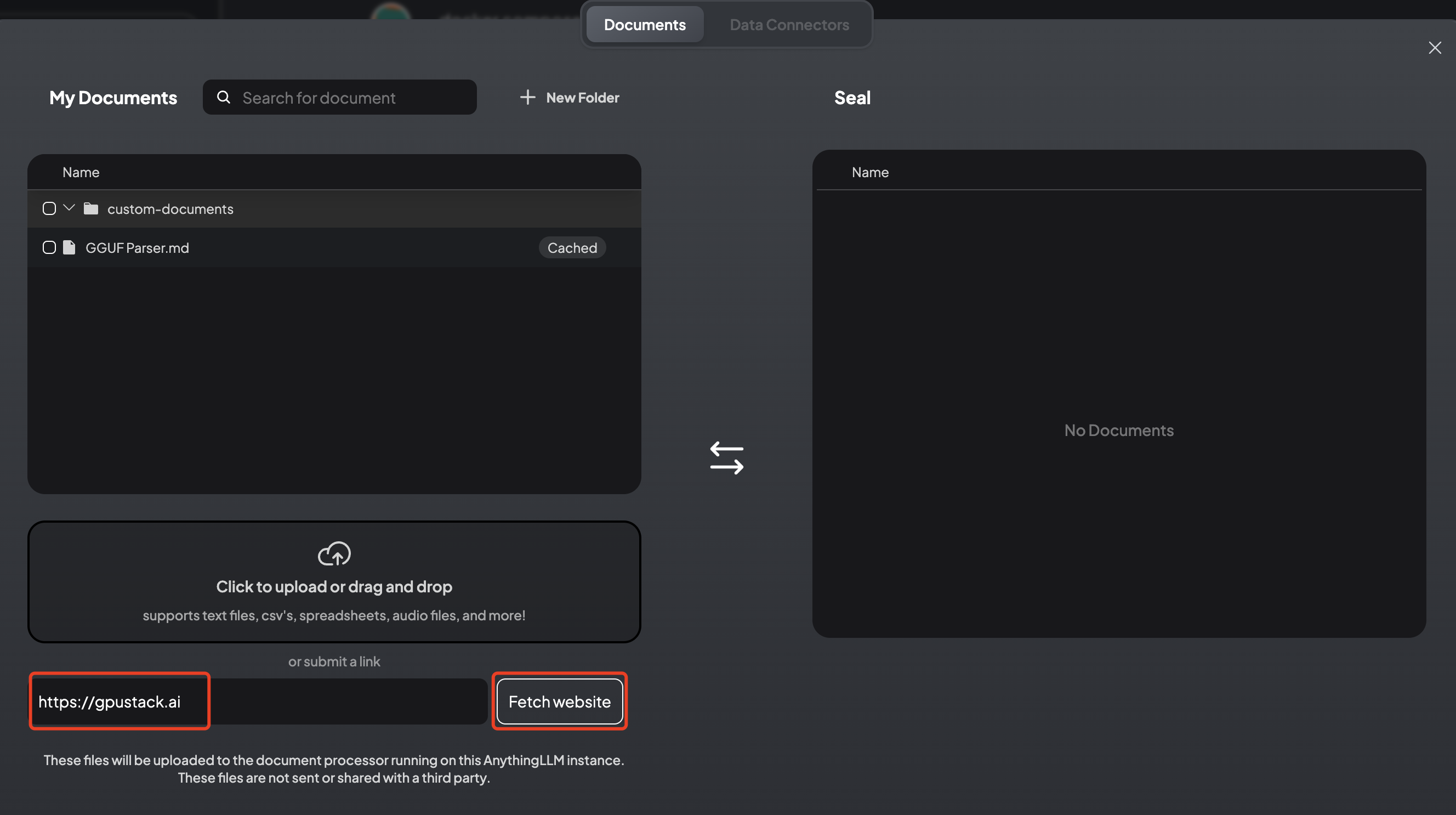
The fetched website content will be sent to the embedding model for vectorization and then stored in the vector database.
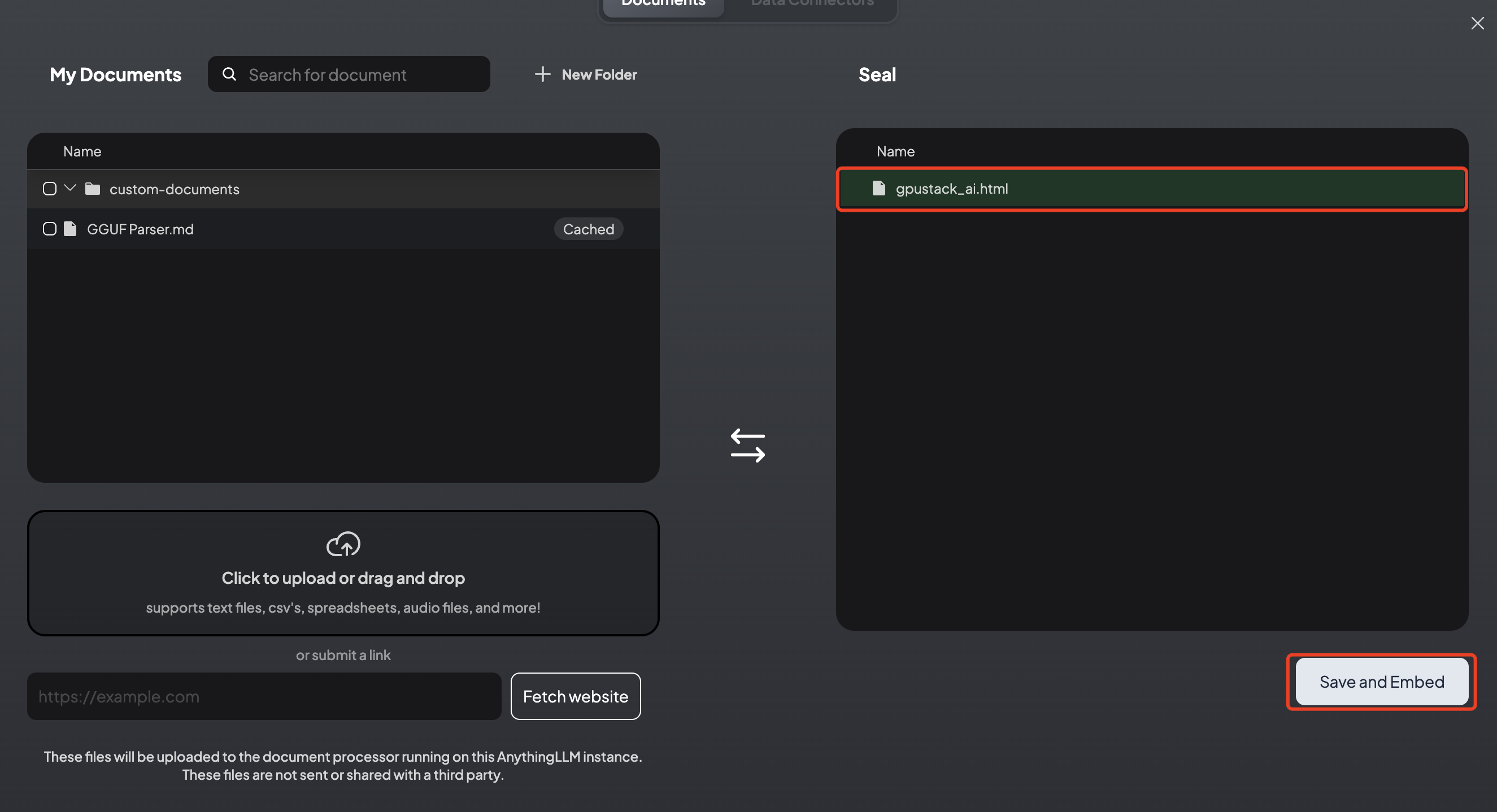
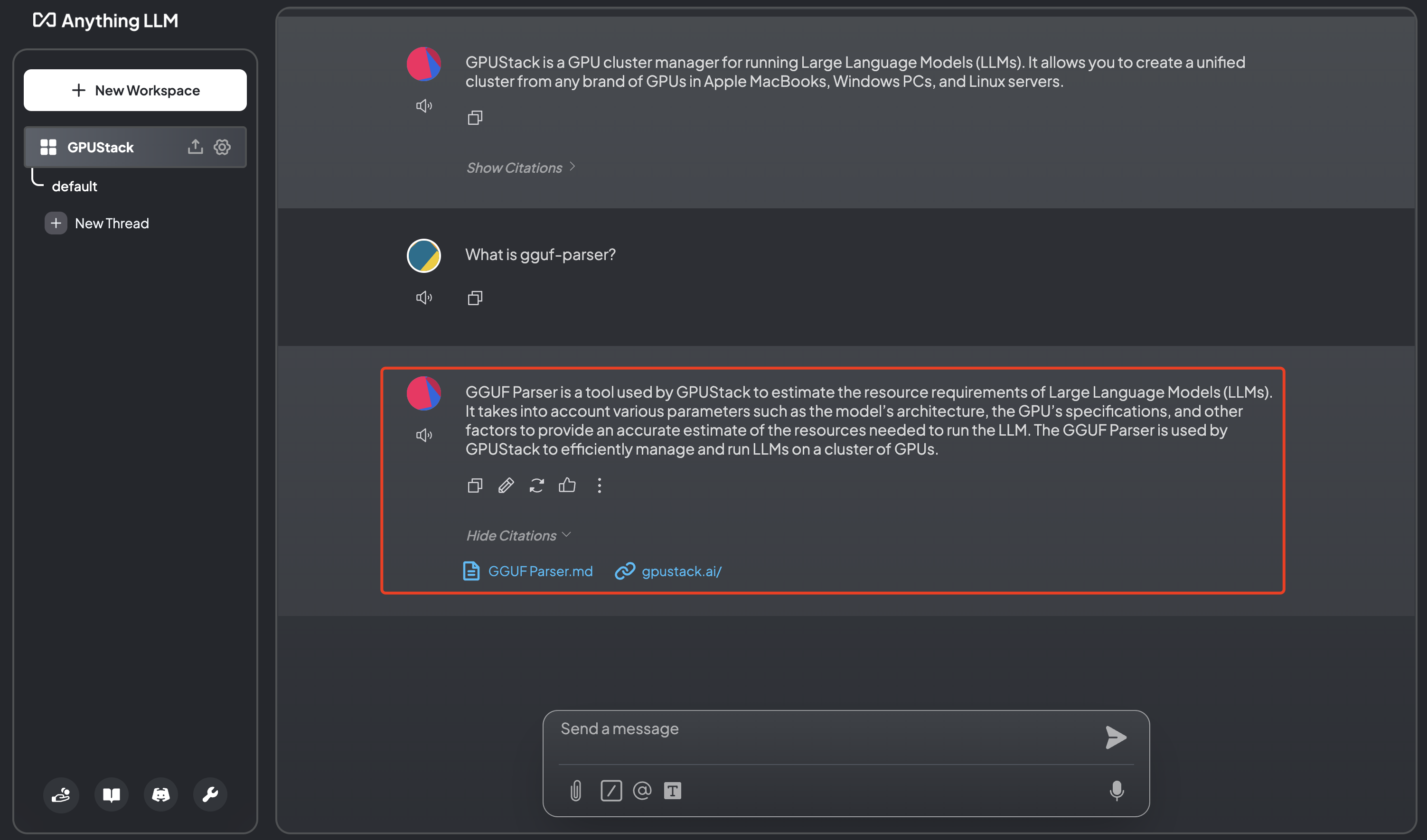
Check the content fetched from the website:
Documents embedding
Click the upload button next to the workspace, then click the upload box and upload a document. The document will be sent to the embedding model for vectorization and then stored in the vector database.
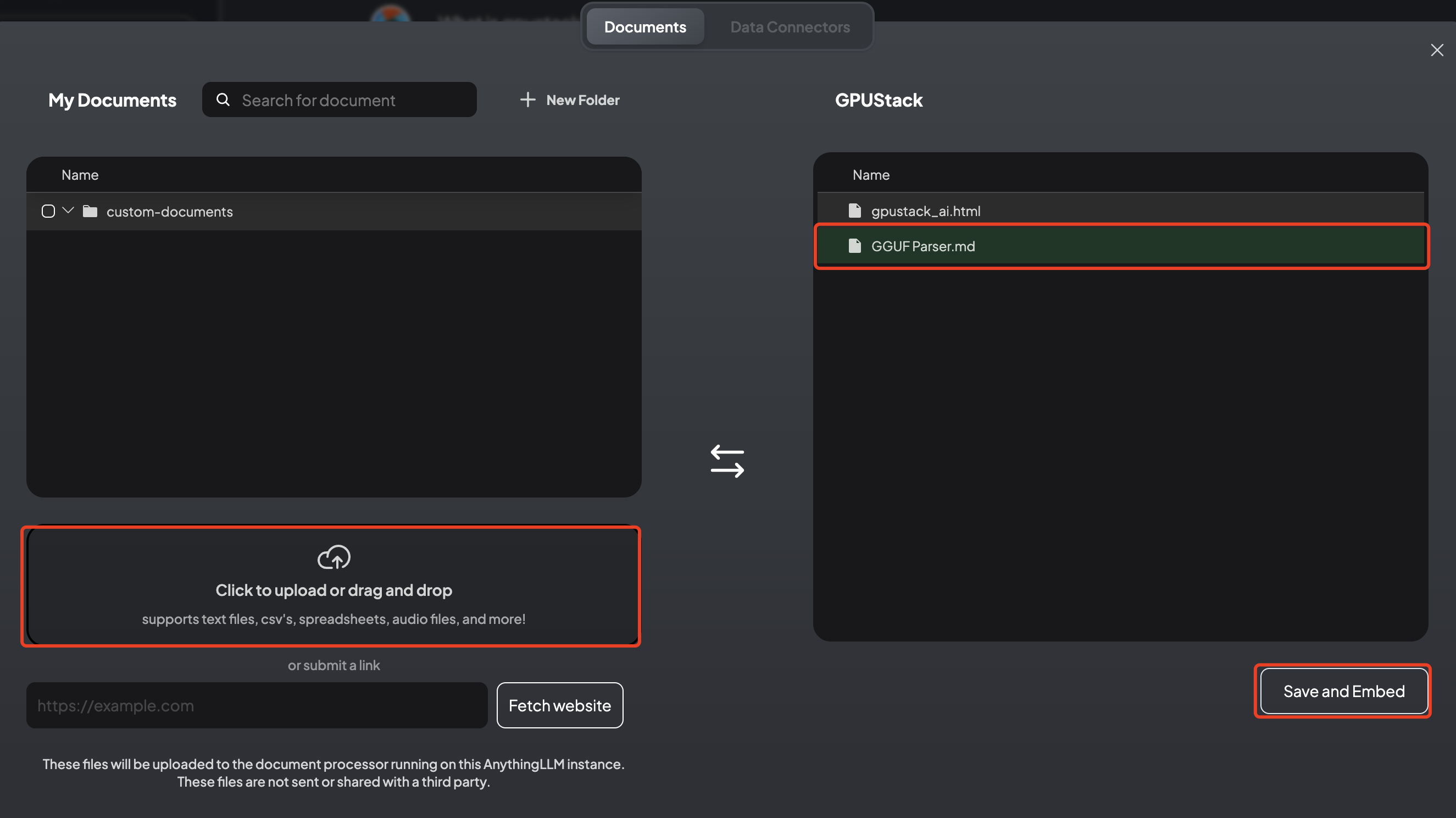
Check the content of embedded documents:
For more information, please read the AnythingLLM documentation: https://docs.anythingllm.com/
Conclusion
In this tutorial, we have introduced how to use AnythingLLM + GPUStack to aggregate GPUs across multiple devices and build an all-in-one AI application for RAG and AI Agents.
GPUStack provides a standard OpenAI-compatible API, which can be quickly and smoothly integrated with various LLM ecosystem components. Wanna give it a go? Try to integrate your tools/frameworks/software with GPUStack now and share with us!
If you encounter any issues while integrating GPUStack with third parties, feel free to join GPUStack Discord Community and get support from our engineers.













{kind=link}